The story so far - this is an experiment in 'open research' - I'm going to blog my research on a particular topic. In this post, I'm outlining the high level goals for the project.
Executive Summary
Find better ways to exploit the information that are contained in social
tags, especially social tags that are applied to music, in order to
provide tools to allow an individual to explore a complex space.
Details
Most music recommendations are of the form - 'here's a set of
artists or tracks that you might like', or 'if you like "weezer" you
might like "cake". They don't offer any reasoning behind the
recommendation. These types of recommendations may be appropriate if
you are shopping for music at AmazonMp3 or iTunes, but it really is a
horrible way to go about exploring for new music.
 Music is a very rich space. There are hundreds or thousands of
overlapping genre and subgenre. The meaning of a genre changes overtime
("Pop" of 2000 is very different from "Pop" of 1970). Some artists
define their own genre, other artists span many genres. There's no
single "correct" taxonomy of genres - experts don't even agree on the
most basic questions about genre such as where does 'pop' end and 'rock'
begin. Genre is complex - and yet it is only one axis of this
complex music space. There is also mood, era, lyrics, artist influence,
popularity and on and on.
Ultimately, I'd like to build a discovery tool that will allow a user to
easily explore a rich space such as music. Unlike a traditional
recommender that is tailored for a music shopper, this discovery tool
would be tailored to someone who is exploring for the enjoyment of
discovery. Ishkur's Guide to Electronic Music is an excellent example of the type of interface I am interested in building.
Music is a very rich space. There are hundreds or thousands of
overlapping genre and subgenre. The meaning of a genre changes overtime
("Pop" of 2000 is very different from "Pop" of 1970). Some artists
define their own genre, other artists span many genres. There's no
single "correct" taxonomy of genres - experts don't even agree on the
most basic questions about genre such as where does 'pop' end and 'rock'
begin. Genre is complex - and yet it is only one axis of this
complex music space. There is also mood, era, lyrics, artist influence,
popularity and on and on.
Ultimately, I'd like to build a discovery tool that will allow a user to
easily explore a rich space such as music. Unlike a traditional
recommender that is tailored for a music shopper, this discovery tool
would be tailored to someone who is exploring for the enjoyment of
discovery. Ishkur's Guide to Electronic Music is an excellent example of the type of interface I am interested in building.
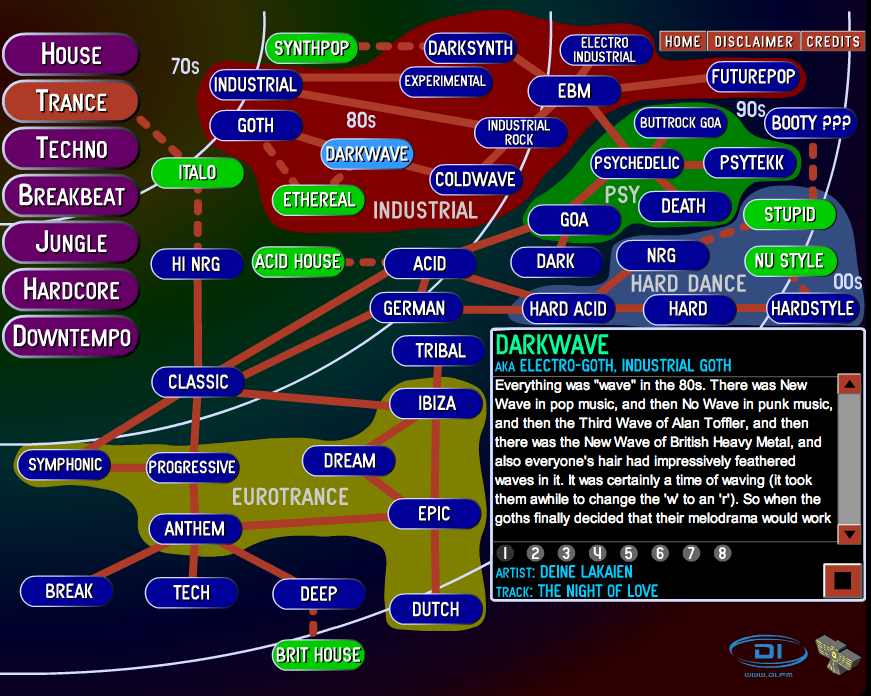
In this one interface is captured the a very rich view of the world of
electronic music. There is decade information, high level genre,
subgenres, genre dependencies, with examples from multiple artists for
each genre along with reviews of the artist or genre. I'd like to be
able to build an interface similar to Ishkur's automatically using data
that is available from sites like Musicbrainz, Last.fm and All Music.
A first step toward this goal is to be able to find information about
how various genres and sub-genres overlap. Professionally curated
genre hierarchies such as what you'll find at All Music, Mp3.com, Amazon
or iTunes, tend to be small and flat and don't show any kind of
overlap. The genre hierarchy embedded in the wikipedia is richer, but
still doesn't show how the various genres overlap.
For this first step I want to build a rich representation of the genre
space automatically from data mined from the web. This rich
representation includes:
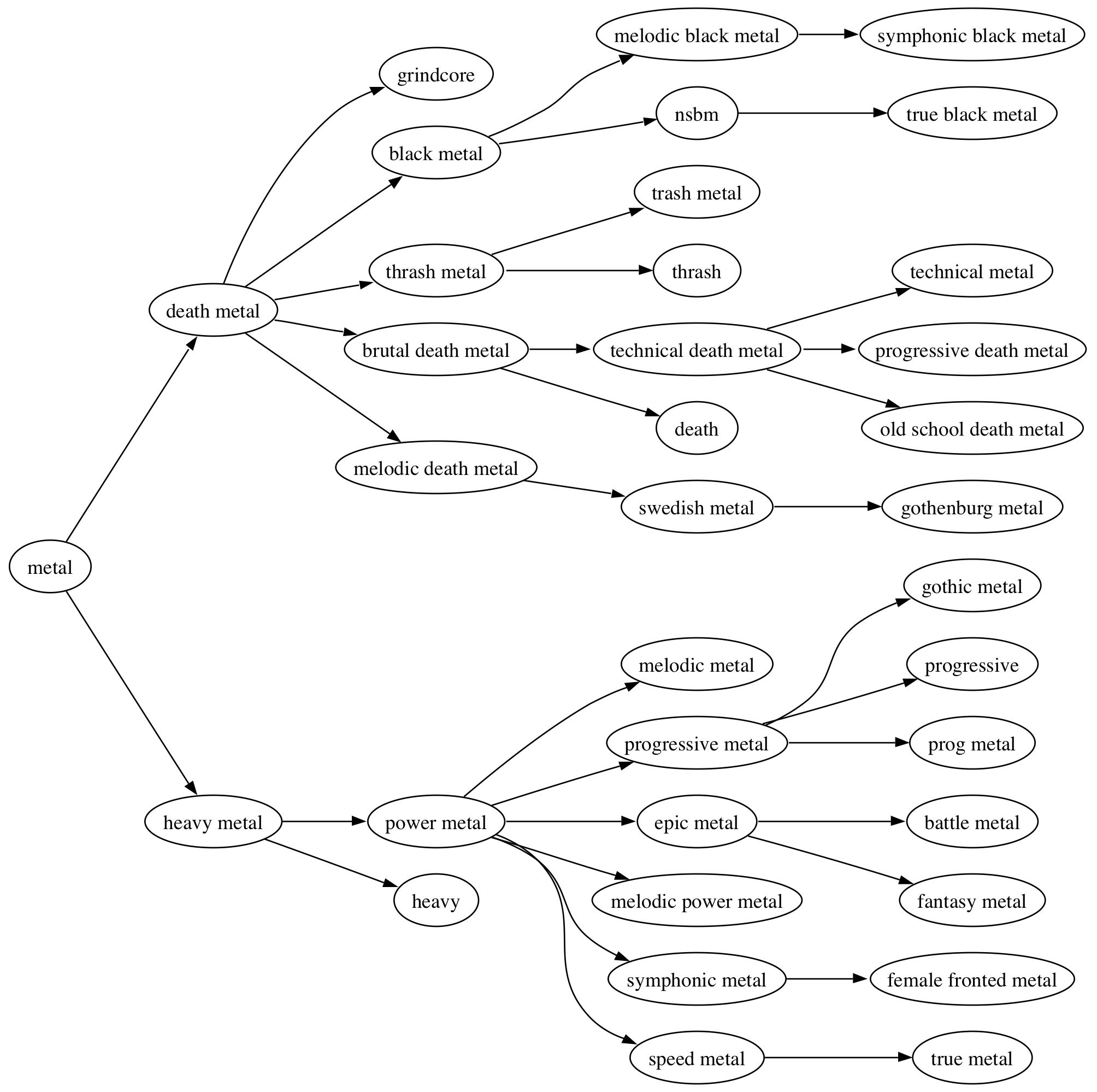
- Identifying the set of genres and subgenres that people actually use. (i.e. is 'Brutal Death Metal' really a genre?).
- Distinguish genres from other types of music descriptions such as mood, locale
- Identify overlaps in genre (how much if at all does 'emo' overlap with 'punk'?, Is 'alternative' just a new name for 'rock'?)
- Create a hierarchy of genre. Hierarchies are a natural way to
explore a space - A hierarchy allows an explorer to start from with the
general and move to the specific. The hierarchy may be a mono- or a
poly- hierarchy.
- Identify synonyms (Are 'hip hop', 'hip-hop' and 'rap' identical?)
- Disambiguate terms (Does 'progressive' mean the same when it is
applied to 'progressive rock', 'progressive jazz', and 'progressive
metal'?)
- Identify changes in genre meaning over time (Is 1960s 'Ska' the same as 1980s 'Ska'?)
- For each genre, what are good exemplar artists/tracks for the genre? Are tracks from popular artists better exemplars?
I want to build this rich representation of genre from data mined from
the web, without any human intervention, so that as the genre space
evolves overtime, this genre map will automatically evolve as well.
I've done some early experiments generating genre mono-hierarchies from
Last.fm artist tags with promising results. (
See this post).
However, there is much work to be done to turn that experiment into a
real system that that can take a big bucket of social tags, separate the
wheat from the chaff, and turn them into a representation that can
guide visualization and exploration of the music space.
Next steps - we need to do some background reading, in particular we need to explore a number of areas:
- Music seeking behaviors - to understand better how having a
rich representation of genre might be used to enhance music discovery
(transparency, play)
- Genre Hierarchy - explore the issues involved in trying to represent genre in hierarchies or overlapping graphs
- Text techniques - we will need lots of text mojo here (disambiguation, clustering, latent semantic analysis, etc.)
- Evaluation - we need some way of evaluating our results
- Visualization - how do we visualize a complex, overlapping, polyhierarchy?
I am interested in all kinds of feedback. A big goal for me with this
'open research' is to get early feedback. Likewise, suggestions for
background reading on the aforementioned topics (or any others that seem
relevant will be helpful). In a future post, I'll put together the
reading list for anyone that wants to follow along.



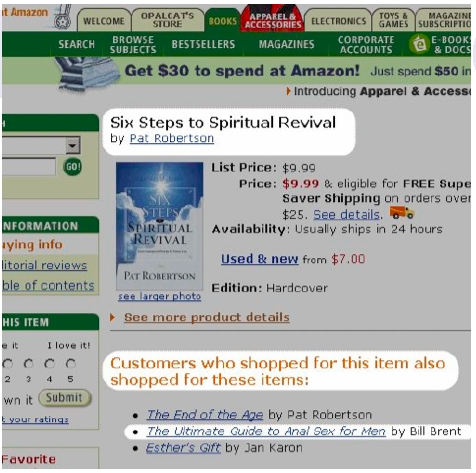

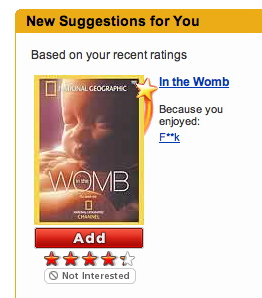 Because you enjoyed
Because you enjoyed